
Dezember 2016 - DataMining ist absolut faszinierend
Es ist Tag 2 des 33C3 und ich sitze in Saal 2. Gerade habe ich meine ersten Erfahrungen im Sub-tiltlen gesammelt und lausche nun dem Talk von David Kriesel "SpiegelMining": Öffentlich verfügbare Daten einfach mal tiefer analysieren und neue Schlüsse daraus ziehen. Ich bin absolut fasziniert von den Möglichkeiten und begeistert von den Techniken und Tools. Schnell reift der Gedanke: "das will ich auch!"
Stellt sich nur die Frage: woher kommen die Daten?
Einfach ebenfalls auf SpiegelOnline setzen wäre nicht das Richtige. Und erst ein Jahr Daten aufzeichnen zu müssen, bis es richtig losgehen kann, dauert mir irgendwie zu lange; da würde ich schon gerne direkt durchstarten. Also müssten es schon vorhandene Daten aus einem Archiv sein.
Womit kann ich arbeiten?
Der Entschluss ist gefasst: Der Heise-Newsticker will analysiert werden. Also ran an die Daten.
Betrachet man eine typische HeiseNews-Seite, so lassen sich zunächst ein paar klassiche Informationen für die spätere Analyse finden:
- Titel
- Datum/Uhrzeit der (ersten) Erstellung
- Author
- Anzahl Worte
- Anzahl enthaltener Links

Damit könnten wir vermutlich eine erste Statistik aufsetzen, allerdings fehlt es noch an einer Kategorisierung der Nachrichten für schicke Grafiken und Korrelationen. Hierfür bieten sich bei heise.de mehrere Informationen der Webseite an:

Verarbeitung, Visualisierung und erste Überraschungen
Schon mit den ersten Daten, die in die Datenbank fließen, muss geklärt werden: wie und womit sollen die Daten eigentlich analysiert und visualisiert werden? Die von David Kriesel genutzte Software Tableau kommt eher nicht in Frage. Sie ist zwar mächtig, für ein Privat-Projekt aber dann doch nicht im richtigen Preisrahmen. Auch andere Tools zeichnen sich durch mächtige Funktionen aus, haben aber Linzenzkosten, die zumindest für einen allerersten Blick in DataSience nicht die erste Wahl sind. An freier Software gibt es z.B. FnordMetric, bei dem ich allerdings mit dem Datenimport aus der MySQL-DB nicht klar gekommen bin, oder das gute alte R. Hier habe ich mich ein wenig drin versucht, aber neben der Kommadozeilen-Komplexität stellte auch hier die Arbeit mit den SQL-Daten eine Hürde da.
Schließlich bin ich bei ElasiticSearch und Kibana gelandet. Die Elastic-Suite ist ebenfalls sehr mächtig und darüber hinaus OpenSouce. Nach erster Skepsis zeigt sich schnell, dass zumindest die vorrangigen Fragen schnell, einfach und optisch ansprechend beantwortet werden können. Gesagt, getan: Die gecrawlten Daten landen -- leicht aufbereitet -- in einem ElasticSearch-Index und können fortan mit Kibana sehr einfach analysiert werden. Zum Beispiel die Betrachtung der Anzahl der Artikel pro Wochentag und Stunde:
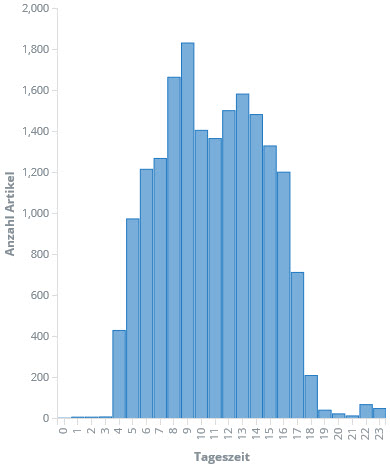
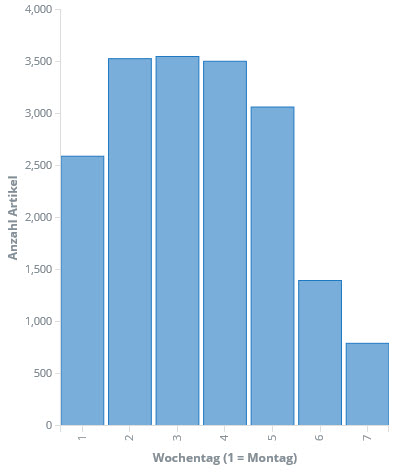
Man kann schon erkennen: Ab vier Uhr morgens geht es los und zwischen 17:00 und 18:00 ist Feierabend für die meisten. Auch die Verteilung über die Woche ist erwartungsgemäß. Überraschend ist vielleicht, dass die Woche doch eher verhalten beginnt.
Seite 1 von 2